Project · Live — orchemist.com
Orchemist — Orchestration Engine
Orchemist is a production-grade orchestration engine built from real experience running AI agents across coding pipelines, content workflows, and translation systems. Not a framework — an engine that actually runs.
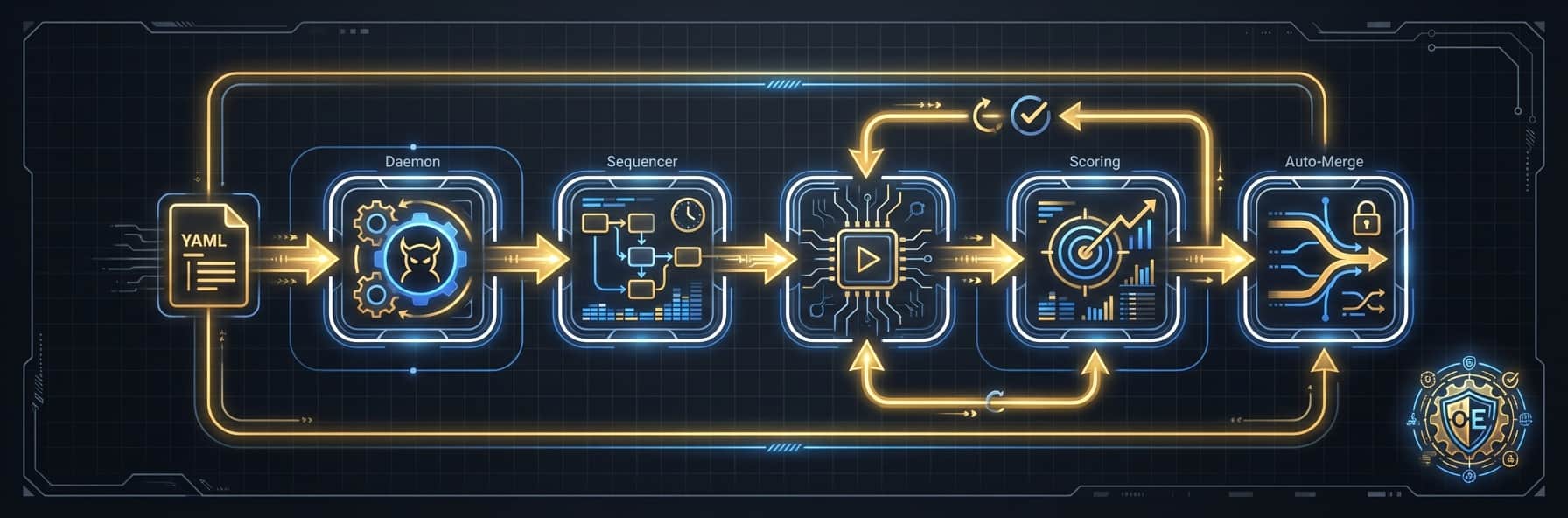
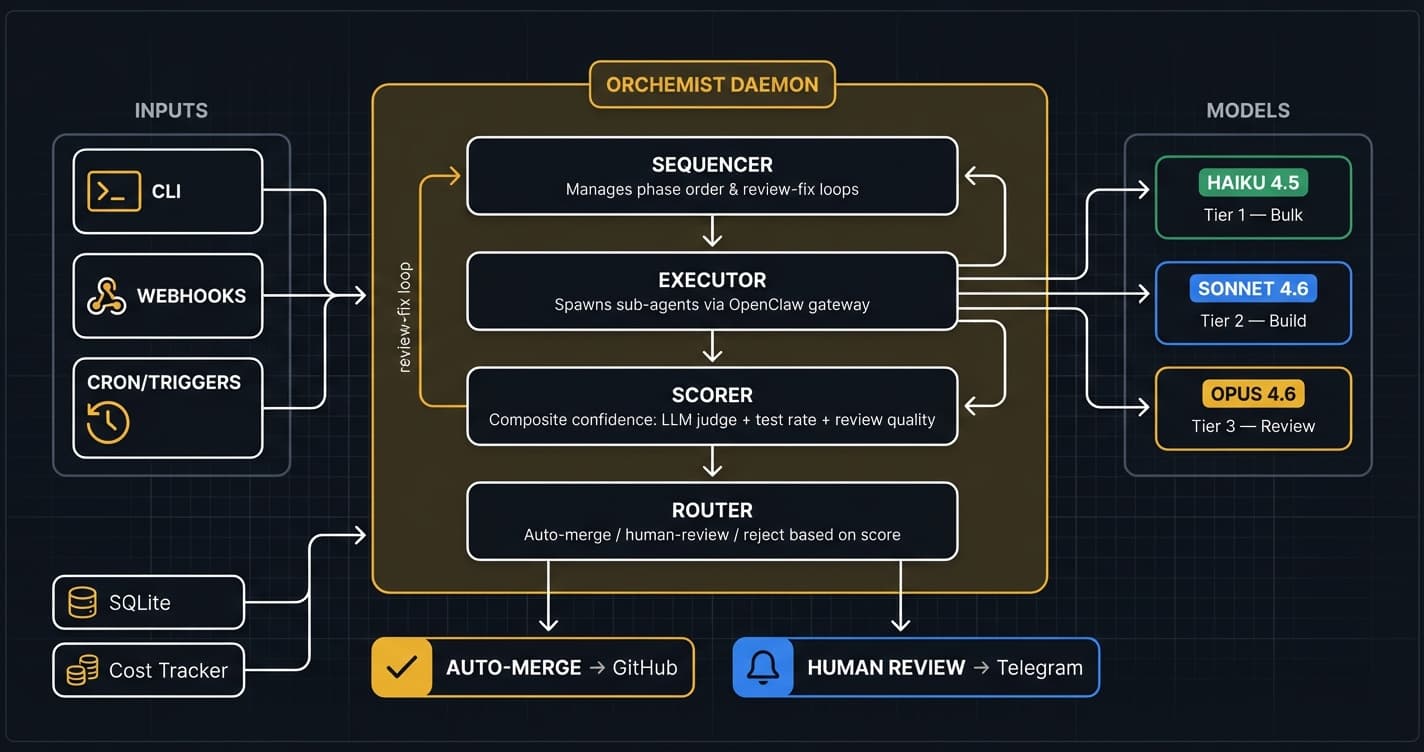
Define multi-phase pipelines in YAML with dependency graphs, model tier routing (Haiku/Sonnet/Opus), and automatic output forwarding between phases. The sequencer uses topological sorting for execution order and supports review-fix loops with configurable iteration limits.
Quality is enforced through a composite confidence scoring system: LLM judges (rubric-anchored blind evaluation), test pass rates, review quality metrics, and change complexity analysis. Scores above threshold auto-merge; below routes to human review.
The coding pipeline runs spec → implement → review → fix → test → score in ~15-30 minutes. Opus catches real bugs in review (path traversal, injection, regression). Sonnet implements. The review-fix loop iterates until APPROVE or max iterations.
Six sprints completed: 50+ issues shipped, 5900+ tests passing, 0.993 average quality score. Includes webhook triggers, pipeline chaining, confidence routing, sprint runner templates, and a daemon with cost tracking. All code written by AI agents, reviewed by Opus, approved by human.
Built on Python 3.10+ with minimal dependencies (Pydantic + PyYAML + SQLite). Runs on anything from a laptop to a Raspberry Pi. Going open source — Apache 2.0, targeted after reaching Level 5 (Dark Factory) autonomy.
Architecture
Diagrams
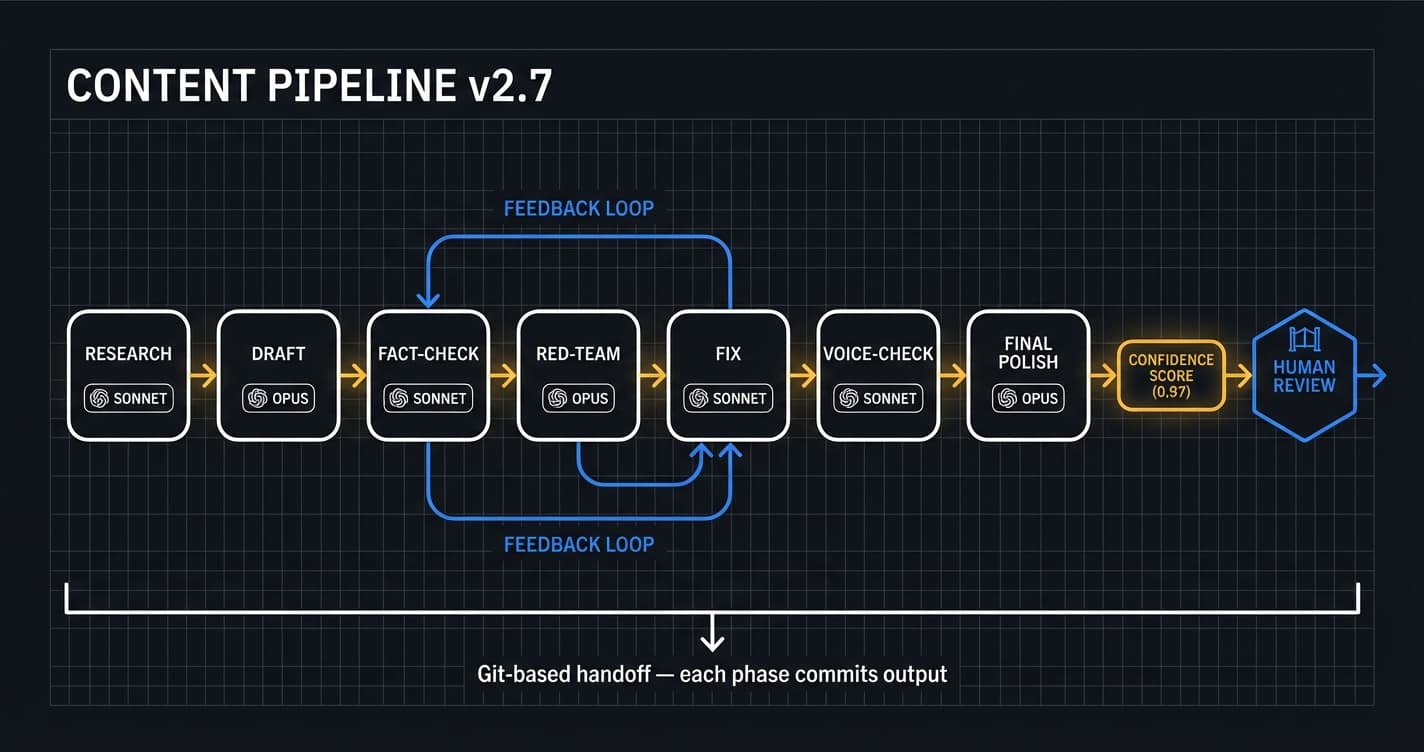
The content pipeline runs 7 phases from research to final polish, with fact-checking and red-team review built in.
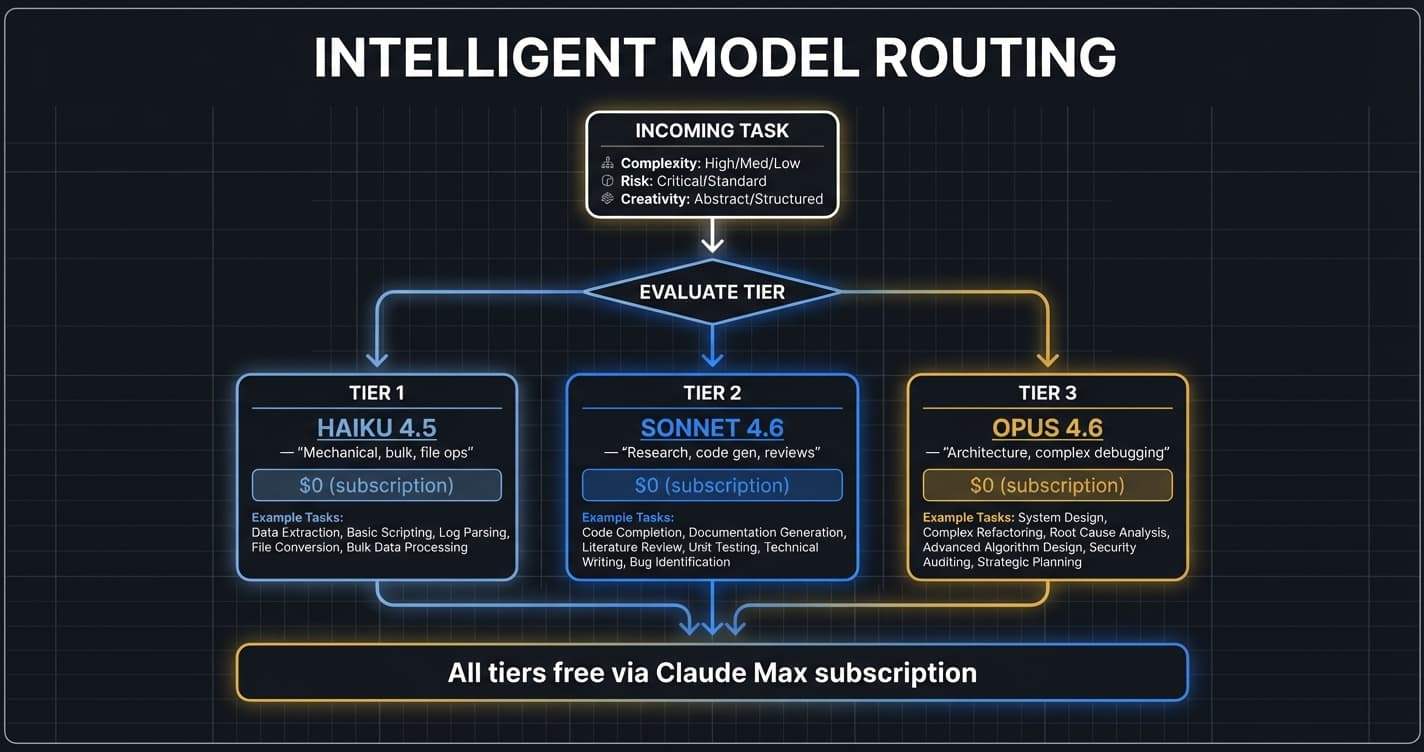
Route by complexity: Haiku for bulk ops, Sonnet for code gen and reviews, Opus for architecture and high-stakes decisions.

Six sprints completed with zero manual code. Every line written by AI, reviewed by Opus, approved by human.
Tech Stack
Key Features
- ✓YAML pipeline definitions with topological dependency sorting
- ✓Phase sequencer with review-fix loops and output forwarding
- ✓Three model tiers: Haiku 4.5 (bulk), Sonnet 4.6 (balanced), Opus 4.6 (heavy)
- ✓OpenClaw executor — spawns sub-agents via gateway API
- ✓Composite confidence scoring with auto-merge routing
- ✓Webhook triggers for CI/CD integration
- ✓Pipeline chaining — completion of one triggers the next
- ✓Sprint runner meta-template for sequential issue processing
- ✓Background daemon with cost tracking per phase
- ✓Content pipeline v2.7 — 7-phase with fact-checking and red-team review
- ✓Coding pipeline v1.2 — spec/build/review/fix/test with Opus code review
- ✓5900+ tests with full security coverage
- ✓Git-based handoff between pipeline phases
- ✓Runs on anything — laptop, server, or Raspberry Pi
Challenges
The biggest challenge was closing the gap between 'tests pass' and 'ships production code autonomously.' Early pipelines produced hallucinated content that cost real credibility. That failure led to the multi-agent review architecture: separate agents for writing, fact-checking, and adversarial review. The confidence scoring system emerged from real bugs — a 0.60 score isn't a calibration problem, it reflects genuine issues the review caught. Every protocol exists because we shipped something broken without it.
Agent Orchestration
9 articles on multi-agent systems, harnesses, and orchestration patterns.

From Factory to Dark Factory: The Orchemist Roadmap (And Why V1 Will Build V2)

Getting Orchemist Running in 10 Minutes — And Why You'll Talk to It Instead of Typing Commands
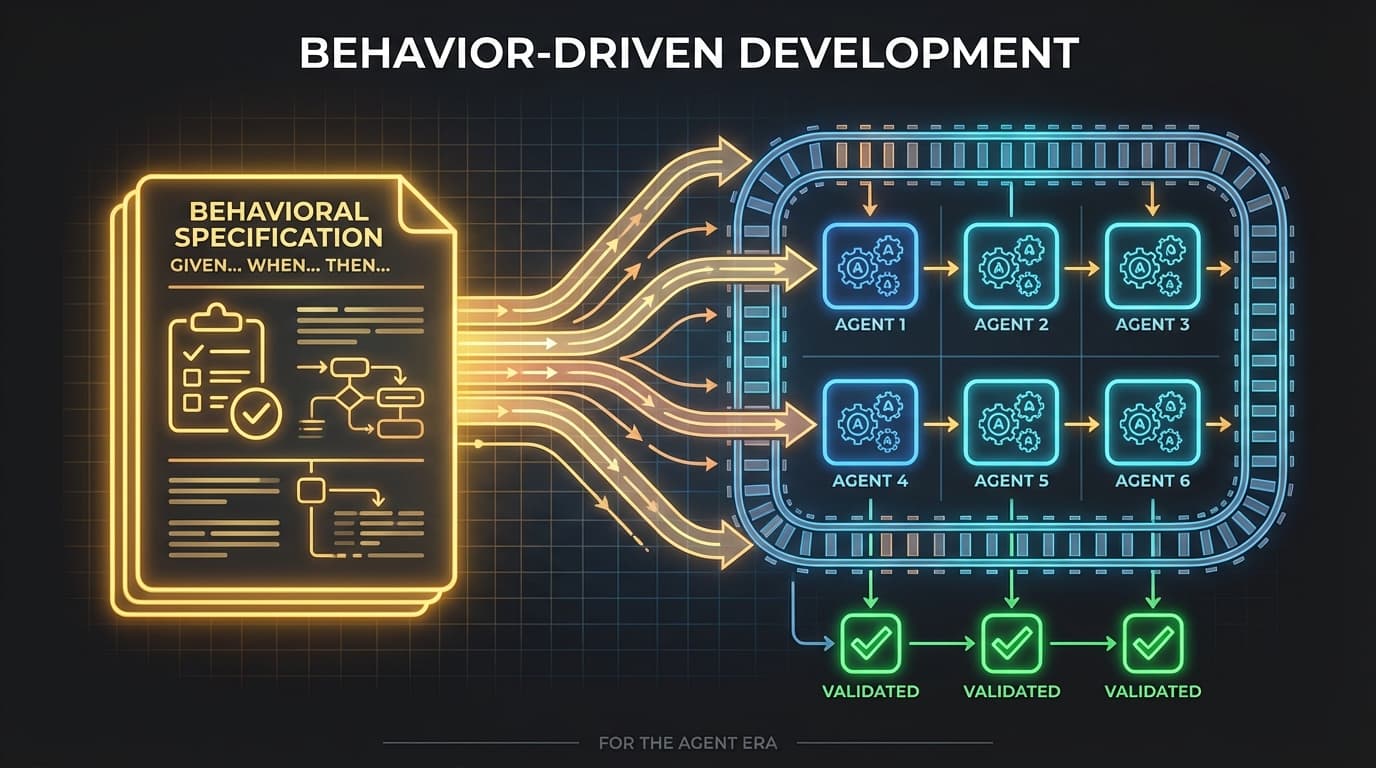
When AI Writes the Code, Who Checks the Homework? Behavior-Driven Development for the Agent Era
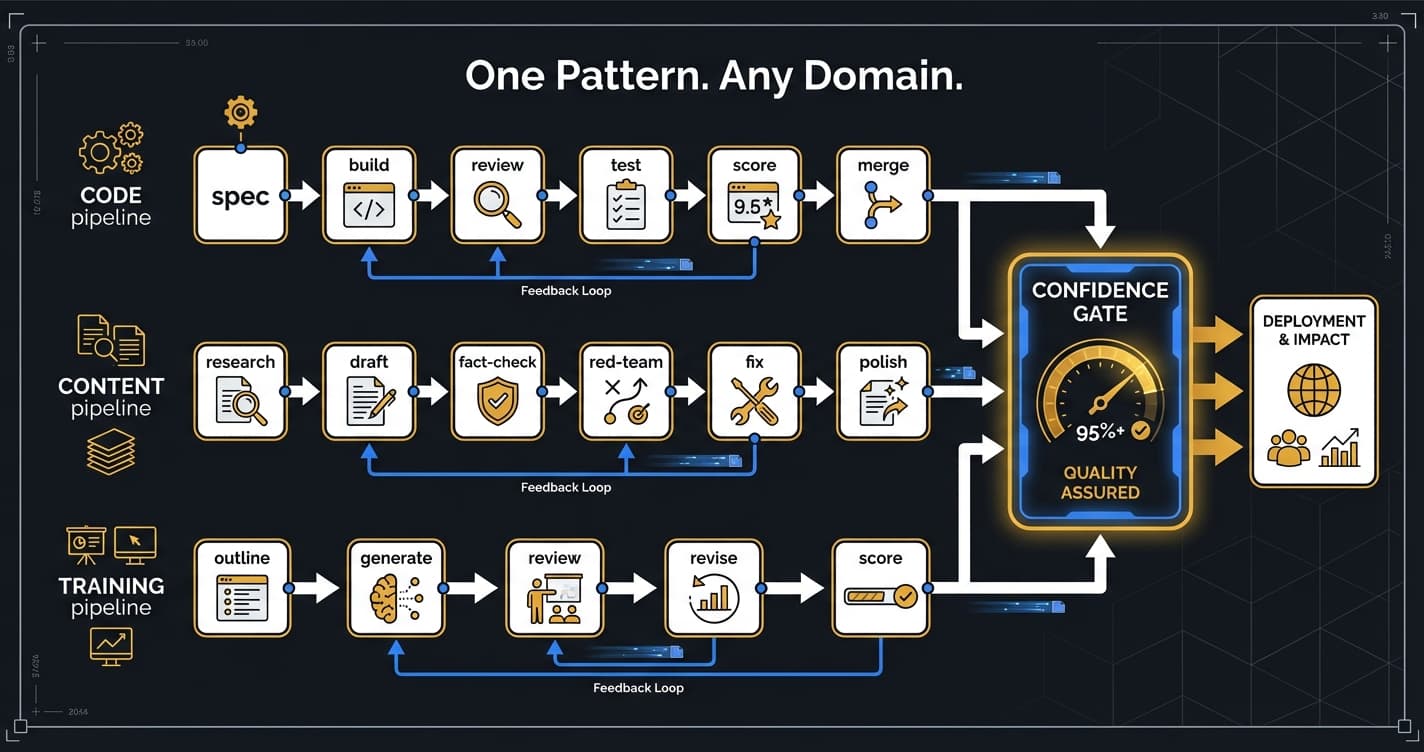
Orchemist Doesn't Just Write Code — It's a Trust Factory for Anything AI Touches
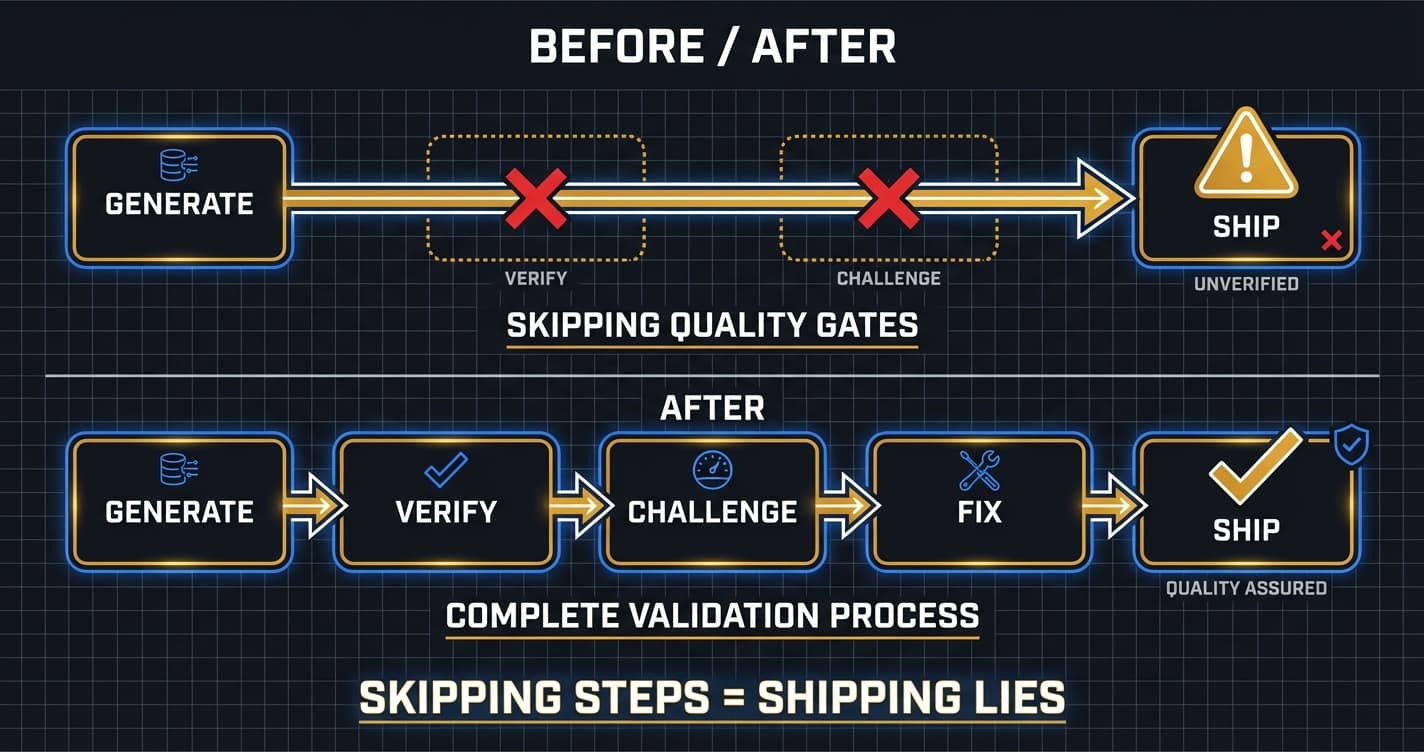
I Published AI Content Without Challenging It. Then I Built a System That Won't Let Me Do It Again.

The Agent Memory Wall: Why Better AI Still Needs Better Humans

4 AI Labs Built the Same System Without Talking to Each Other

Twenty Minutes Apart, Two Futures: Why I Chose Coordination Over Delegation
